If you prefer reading in English, there is a magical switch on the top-right corner.
本网站没有使用Python。
If you prefer reading in English, there is a magical switch on the top-right corner.
本网站没有使用Python。
本文是续在Cambricon-U之后的短小随想。
RIM体现了我们作为并不研究存内计算的研究者,对于存内计算的新认识。 提到存内计算概念,人们直觉上首先与冯·诺依曼瓶颈联系起来,并认为存内计算当然是解决瓶颈的不二法门。 除了业余的计算机科学爱好者,也不乏专业的研究者以这种口径撰写各类材料。
这是错误的。
在RIM的心路历程中,我们展示了过去的存内计算缘何不能支持计数,而计数(后继运算)乃是皮亚诺算术系统中的公理元素,是算术之基础。 我们通过取巧的办法,利用了一种体系结构领域学者并不熟悉的记数法,才首次实现了存内计算的计数功能。 但是这种取巧只能取一次,无情的自然不会允许我们第二次取巧成功,因为想要在电路中同时高效实现加法和乘法的记数法已被证明不存在*。
计算需要信息的流动,而存内计算要求它们呆在原地,这天然是矛盾的。 结合姚先生的结论,我们恐怕无法真正在一个存储阵列中高效地原位完成冯·诺伊曼机所需的各类计算。 让我预测的话,存内计算永远不会和冯·诺依曼瓶颈真正产生关系。
* Andrew C. Yao. 1981. The entropic limitations on VLSI computations (Extended Abstract). STOC’81. [DOI]
在MICRO 2023大会上,我们展示发明了一种新型存内计算器件“随机自增存储器(RIM)”,并将其应用于随机计算(一进制计算)架构中。
在学术界,存内计算是当前火热的研究领域,常被研究者寄予突破冯·诺依曼瓶颈、实现计算机体系结构大变革的美好期望。 但目前,存内计算这一概念的涵义却逐渐收敛于特指采用忆阻器、阻变存储器(ReRAM)等新材料、新器件完成矩阵计算这种特定计算功能。 在2023年,在我们这些原来并不研究存内计算的外行研究者看来,存内计算发展到了一个很奇怪的境地:已经发展出的存内计算设备能够很好地处理神经网络、功能类比大脑,却仍然无法做诸如计数、加法这样最基础的运算。 在Cambricon-Q的研究中,我们留下了一个遗憾:我们设计了NDPO在近存端完成权重更新,却无法做到真正的存内累加,因此被评阅人批评“只能称为近存计算,而非存内计算”。 由此,我们开始了对于如何在存储器内完成原位累加的思考。
我们很快意识到,如果采用二进制记数,加法是很难在存储器内原位完成的。 这是因为加法虽然简单,但存在进位传播:即使是对存内数值加1,也有可能导致所有比特全部发生翻转。 因此,在集成电路中制作计数器,需要一个完整的加法器来完成数值自增操作(后继运算),存储器内完整的数据必须全部被激活备用。
好在自增操作在平均情况下只会导致两个比特的翻转。我们需要找到一种记数法,控制最差情况下可能发生翻转的比特数量。因此我们引入了偏斜二进制记数法来代替二进制。偏斜记数法最初提出时是用于数据结构设计,例如用于Brodal堆,控制堆发生归并时的最差情况时间复杂度,而这与控制加法的进位传播十分类似。
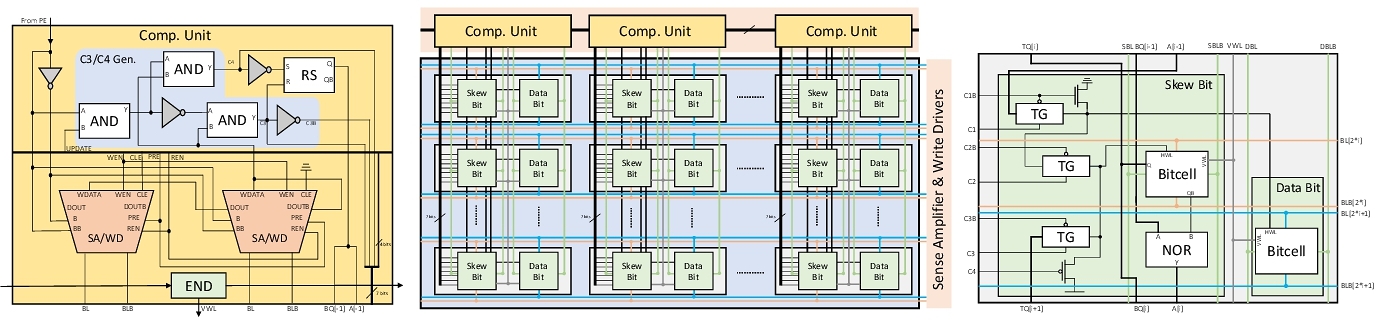
我们使用CMOS上的SRAM技术作为基础来设计RIM。我们将存储的数值(以偏斜记数法记录)按列向存储,并为每一列额外提供一列SRAM单元格用来存储每一数位的偏斜状态(即偏斜数中的数位“2”)。偏斜数的自增操作规则如下:

虽然每一个数中的“2”所处的行可能不同(偏斜记数规则中要求一个偏斜数中最多只能有一位为“2”),导致要操作的单元格随机分布在存储器阵列里,不能按以往SRAM的行选方式来激活;但我们可以使用上一位的偏斜状态来激活本位和下一位的对应单元,实现在同一操作周期中激活出位于不同行的单元格!
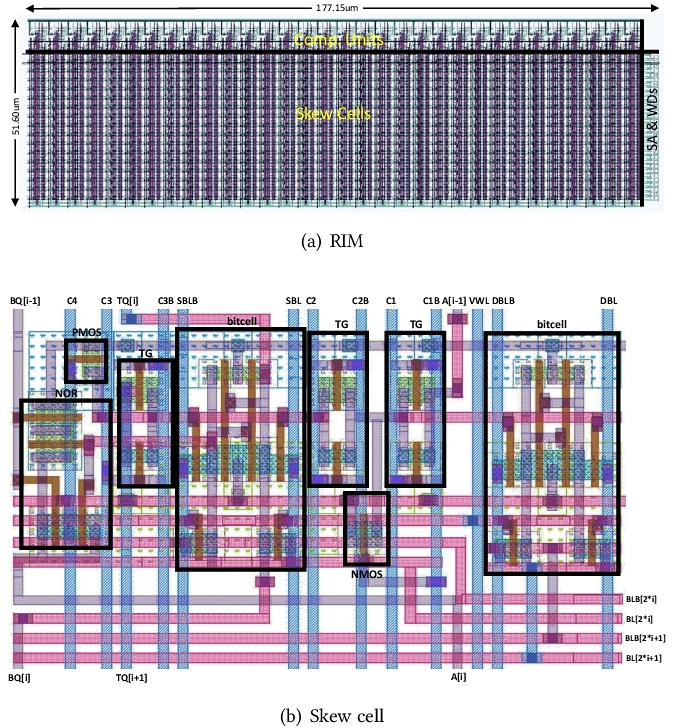
最终,我们实现了24T的RIM单元格——没有使用新材料,而是完全由CMOS技术构建。RIM能够实现对所存数据的随机自增:在同一操作周期里,RIM所存储的一些数据可以按需自增,而其他数据可以保持不变。
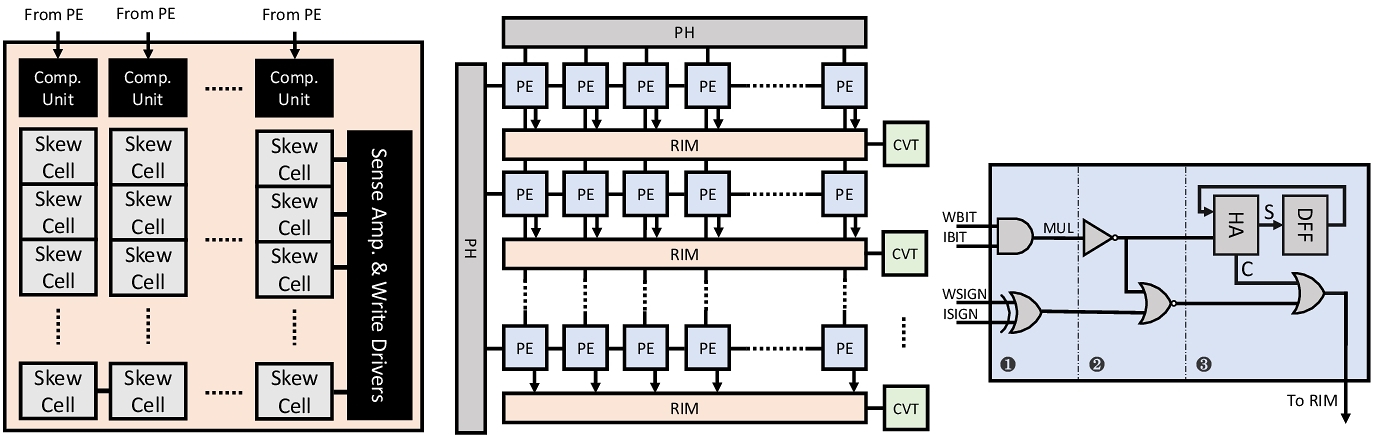
我们将RIM应用于随机计算(一进制计算)中。 随机计算的一大痛点在于一进制数与二进制数之间的转化开销——二进制数转一进制数需要随机数发生器,一进制数转二进制数需要计数器。因为一进制数数位太长(可达上千比特),使用一进制数完成计算后,中间结果如需暂存,必须转换回二进制,使计数操作所消耗的能量甚至能达到整个计算架构的78%。 我们使用RIM替换了uSystolic中的计数器,构建了Cambricon-U架构,显著降低了计数操作的能耗。 这项工作解决了基于随机计算的深度学习处理器的一项关键痛点,使相关技术有望更快应用。
论文发表在MICRO 2023。[DOI]
整个五月都在帮人改文章当中度过。
在我们的教育体系里,学生写研究生学位论文之前,从来没有人教过他们怎么写。这导致了很多问题:学生不会写,老师改得痛苦;千叮咛万嘱咐,改了一版又一版,一两个月过去了,答辩完还是被逮捕。大部分文章出现的问题都是共性的,然而却需要我们每个人手把手地教,非常费时费力,效果也不好。我总结一部分共性问题,供有需要的同学自查自纠。
为了方便完全不懂写作的同学也能意识到问题,我给出的都是非常表面、浅显、刻板的现象,全部是写个寥寥几行的脚本就能计算出来的指标。请注意:不出现这些现象不意味着论文就能过关,出现了也不意味着一定就不是优秀的论文了。希望能引起读者自己的思考,考虑一下为什么问题论文浮现出的表面现象大多是这样的。
“极”当然可以作为极限的意思在科学术语当中使用,但更多时候,论文里用“极”、“很”、“非常”等等词汇只是为了表达强调。 在语言中,这些词汇的作用是输出情绪,属于主观成分,而对客观地描绘事物几乎没有帮助。 论文作为科学的文字载体,必须保持客观。 写下这些主观描述程度的词汇的时候,同学们需要引起特别警惕,要着重检查自己是否已经脱离了保持客观这一基本要求。 一般同学一旦犯了这样的错误,会连续犯一大串,给评审专家留下的阅读体验可想而知会是多么的不专业。
类似地,建议同学检查论文里是否出现了其他形式的主观评判,例如“取得了广泛应用”“做出了突出贡献”,或者反过来的“效果有限”之类的词句。 这些是只有评审专家才能讲的,评审是要求专家发表主观意见的过程。论文作者要论述客观规律,没有资格讲自己;除非给出明确而客观的依据,论文作者也没有资格讲别人。
解决方法是提供客观的依据。 比如“效率极高”可以改成“在(某项测试)中效率达到了98.5%”;“应用广泛”可以改成“在情感分析[17]、对话系统[18]、摘要生成[19]等领域得到应用”。
你肯定懒得弄参考文献,从DBLP、ACM DL或者出版商网站上复制一份BiBTeX,粘在一起就用了,最后排版出来的参考文献部分长什么样完全交给不知道从哪拷来的bst文件控制。 最后做出来的效果就是,参考文献项目参差不齐:有的缺项,有的又多出很多意义不明的项目出来。所以,我说粗略数一下每一条参考文献里出现了多少个项目域,算算方差就能体现出论文质量来。 参考文献里的问题可真是五花八门了,花多少时间去整理都整不完,所以最能体现作者对论文的上心程度,区分度很高。 同一个会议名称,有的只写会议全称,有的前面加了主办方,有的后面加了缩写,有的用年份区分,有的用届区分; 明明有DOI,有些参考文献后面又给了个arXiv的URL;标题里大小写混乱,有时还连续出现NVIDIA的一百种写法。 所以写论文到底用没用心,用了多少时间打磨,看一眼参考文献就露馅了。学位会上评定论文的时候时间紧张,一定是先从这个弱点开始查起,想蒙混过关是不可能的。
解决方法只有下功夫自己捋一遍,需要不怕麻烦、多花时间。出版商网站上给出的项目只能参考,BiBTeX只是个排版工具,里面要填什么内容最后还是要靠作者来控制。
汉语里是没有这个符号的,英语里也没有,我所知的人类语言都不用这个符号。 只有代码写多了,把论文当成代码文档来写,论文里夹带了代码碎片才会出现这个符号。 这一条定律是刻画得最准确的,几乎没有反例。
论文写作的目的是向其他人传播你的学术观点。要高效地向其他人传递知识,论文必须先对知识进行抽象和提炼。 总不能抛出一堆原始材料去要求读者自行理解,不然作者的贡献在哪里? 抽象的过程就是抛弃掉与叙事无关的实现细节(代码就是其中最恼人的细节),保留令人眼前一亮的思路和诀窍。 因此,任何一篇好的文章里都不会出现代码碎片,好的作者也压根不会有想以含下划线的名字命名任何概念的想法。
解决方法是补完知识抽象和为抽象概念命名的过程。代码、数据、定理推演如要保留,也扔到附录里去,作为补充材料,不要把他们算作文章里的一份子。
学位论文要求是用汉语写作的,然而差劲的论文特别喜欢在汉语语境里夹杂其他东西。 上一条批判的是夹杂代码碎片(讲不好人话),这一条要批判夹杂所有非汉语的内容(讲不好中国话)。 AlphaGo(阿尔法围棋)不用汉语情有可原,Model-based RL(基于模型的强化学习)就没道理夹生了吧? 今年有两个同学写出这样的话:“降低cache的miss率”,整篇论文变成了夹生饭。 研究生准备毕业了,却连母语都讲不好,显现出了论文的低质量。 论文里用到英文命名的概念一时不知道如何用汉语表达很正常。如果这个概念很重要,你当然应该花时间去寻找它的公允译名;如果是新概念就下点心思起一个专业、准确、可辨识的名字;如果你懒得寻找名字懒得起名,说明这些根本就是连自己也不看重的凑篇幅的废话罢了。
建议发现自己有类似习惯的同学,写作的时候给自己立个规矩:文章里每用到一个汉字、阿拉伯数字和汉语标点符号之外的字符,给红十字会捐一元钱。要让自己往汉语论文里写西文的时候,下意识地产生肉疼的感觉。西文不是不能写,至少不能滥用。
爱因斯坦是这样写公式的:
假如相对论是我们的同学创立的,这个公式可能就变成这样了:
至少也要把文字写在文字模式下吧!用\text或者\mathrm包裹起来,不要变成
不说啥了,体会一下大师的差距吧。为什么别人做出的工作是传世经典,我们的还在挣扎通过学位会审核呢? 做工作的时候没有下心思去简化表述,文字也充满赘语,图片也纷繁复杂,竟然连小小的公式符号都缩短不下去。 复杂度越高,学术美感就越差。
当你凑不够篇幅的时候,堆砌图表总比绞尽脑汁多写点文字来得更快一些。 于是同学们写文章的时候,一写到了实验这一部分,拿起程序调优器(profiler)来一顿截图——连续七八张插图,满屏幕色块花花绿绿,感觉论文的分量霎时间就充足、饱满了起来。 结果评审专家拿到论文一筹莫展,这都是啥?啥?啥? 一堆小色块堆砌在那里,与之配套的文字说明几乎没有,想参透背后的逻辑可比智商测试题有挑战得多啦! 除了作者也就只有鬼能知道这图到底是什么意思了(实际上很可能连作者自己也不知道,只有鬼才知道)。 你的论文大体水准还行的时候,为了避免场面太尴尬,看破不说破,专家也就睁一只眼、闭一只眼,权当你这一段没写了。 论文水准若是不行,你堆砌的这些谜一样的配图怕是会成为让专家丧失信心的最后一根稻草。
我这个指标的计算方法如果算出较高的值,至少说明文章中某一部分图、文搭配的比例出了问题,很可能提示了存在有配图未在文字中予以说明、引用论证的情况。 文章的主体是文字,图、表只是方便直观理解文章内容的辅助工具。 使用图、表首先应注意它的辅助说明性质,是对文字的补充。不能本末倒置,绝不应该出现连续的图、表罗列。 其次,还要注意图、表的直观性。 它们要表达的意义应当明确,能够自述清楚(让专家看第一眼就能理解这份图表想要表达的意图); 图、表较为复杂的时候,应当突出重点,引导读者的注意力。 或者,为复杂的图、表搭配详细的阅图(阅表)指引文字。
承接上一条。写论文的时候,建议抠掉键盘上的PrintScreen——恶魔之键。 在这个键的诱惑下,同学们总是懒得画图,从VCS、NSight、VS Code甚至命令提示符终端之类的软件用户界面上直接截取一部分下来,就作为配图插入论文中了。 结果是几乎逃不脱字号过大或过小、字体不匹配、作图风格混乱、说明文字缺失、重点不突出、简单罗列堆砌原始材料等一系列问题。 虽然其中的问题不一定十分致命,但是给人的观感一定特别差。不论图本身的意义明确了没有,首先就给人留下一个懒散的印象。
从IDE截图的,截下来的内容肯定是代码吧!参见第三、第四定律。 而截取终端里程序执行打印出的调试日志作为配图的同学是最恶劣的,还不如截代码呢。 代码好歹还有语法语义,执行日志是纯纯的占用篇幅、浪费纸墨的内容。
我评价论文的时候,首先会检查这个指标,因为很容易:找到最后一页出现相关工作的位置,手指卡住,合上论文,观察书脊前后两部分的比例。 整个过程可能只需要五秒,却能直观地戳穿同学拿相关工作凑篇幅的现象。 如果论文在这个检查下头重脚轻,注定逃不脱是一篇烂文章。因为要写好相关工作,比写好自己的工作还要难得多! 想象一下,答辩时专家们一边翻阅你的论文,一边努力分出一部分注意力来听你报告。 结果你却迟迟不进入自己的工作内容,浪费十几分钟在介绍一些或人尽皆知的、或陈词滥调的、或和本文工作几乎无关联的内容。 这次答辩的结果一定是非常糟糕的。
深入调研相关工作是需要大量精力和学术积累的。 首先需要对重要相关工作进行发现和筛选。 我们不去歧视科研机构和出版物,毕竟要评价具体工作的分量还是要坚持从客观的科学性评价出发。但引领性工作(在统计意义上)更经常由学术水平领先的机构发表在重要会议和刊物上。 而同学总是引用印度工程技术学院发表在Hindawi开放获取杂志上的文章,该领域开创性的重要工作却出现遗漏,足不足以说明对学科前沿还不够了解? 能够罗列出大量的重要相关工作,同时又避免夹带低水平相关工作,本身就是需要长期学术积累才能做成的一件难事。同学们在学术道路上初出茅庐,功底不够深厚是正常的,此时贪图在相关工作上凑篇幅写得太多太长,总是难免露怯。
其次,对遴选出的相关工作进行综述,本就是一份科学性很强的工作。如果做好,其学术价值不亚于学位论文中某一项研究点。 同学们没有那么多时间精力去梳理,或者还没有掌握进行综述的方法,大多数时候只能对相关工作简单罗列。 其中,掌握得比较好的同学大概能写成这样:
** 2 相关工作 **
2.1 某某甲的研究
某某甲很重要,有很多工作。
谁谁谁提出了啥啥啥,怎么怎么样。
谁谁谁提出了啥啥啥,怎么怎么样。
谁谁谁提出了啥啥啥,怎么怎么样。
但是他们都这样了。我们那样。
2.2 某某乙的研究
某某乙也很重要……
这样的写法至少在一串工作的罗列前后做到了有头有尾,也集中呼应了自己的工作,已经难能可贵了。要知道还有很多同学写不成这个水平,只有其中罗列的部分,有甚者一列就是二三十条。 评审专家若成心想刁难作者让他下不了台,大可以一条一条地展开来问:“这项工作的诀窍是什么?”“这项和前面某一项工作的区别是什么?联系是什么?”“这项工作和你有什么关系?”二三十条问下来,人肯定是问傻了。 毕竟罗列这么多工作,有些工作在作者列上来之前可能根本连文章都没打开过,直接从谷歌学术上复制个BiBTeX项进来就草草了事了。 我列举的三个方面问题对应着相关工作的三个必备要素:关键科学思想或发现、分类学和主题相关性。 一个好的综述,应该做到对每一项相关工作的诀窍能够一句话解释清楚;相关工作从不同维度梳理成多个类别,分类合理、界限清楚;每一类工作之间逻辑关系明确、叙事线索清楚,与文章主题紧密相关。 这是非要作者具有很强的科学抽象、语言凝练能力不可的,需要一段反复的推敲和辩证过程才能成文。
学位论文的第一章只要把大约三个研究点归纳到一起,就已经难倒多数同学了。 所以我特别建议同学们,除非有特别的理解,不要轻易在第二章集中介绍相关工作。这样写特别考验写作能力。建议在各个研究点的论述过程中,在真正引用到相关工作的具体位置上,进行针对性的介绍。 否则同学未经科学写作训练,很容易将集中的相关工作章节写成意义不明的一段凑篇幅的内容。 既然是凑篇幅的内容,文章的正文工作越单薄,为了显得篇幅充足,这部分内容凑得自然也就越多。 这段内容占比越长,通常意味着论文质量越差,也就不难理解了。
另一个凑篇幅的重灾区在于实验部分。 毕竟相比于写文章的痛苦,动动手做实验显得舒适多了。 多设计几个无关紧要的指标,画个柱状图做对比,matplotlib脚本都是现成可复用的; 或者数据列成表格,一行可能都放不下,一下子又多占了许多页面。 还有相当多的同学,想凑三个研究点出来却凑不满,就把实验提取出来堆砌在一起,作为论文的第五章、第三个研究点来写。 作为单独的一章,连续的实验部分至少也是十几、二十多页打底,才不显得单薄。 实验罗列到一起,与相关工作罗列到一起,造成的危害是一样严重的。实验原本用来验证研究内容,现在一些研究内容失去了实验支持,而一堆缺乏组织逻辑的实验数据又堆砌到了一起,再一次构成了意义不明的凑篇幅内容。 第九定律提出的是特别为检查这一常见做法而设计的指标。
这种心态应该归结于两点。
其一,经验主义认识的盛行:只将实验看作科学研究的一等公民,从而忽略了建立和传播科学抽象的价值。 作为物理学前沿研究的重要基础设施,北京正负电子对撞机已经产生了超过10PB的实验数据。 很多重要科学发现最初都来源于这些原始数据。 将这些数据印刷编纂成册,一定会成为科学价值极高的著作,让物理学家人手一套吧? 不然。 因为人类用符号语言传递信息的带宽只有约39bps,100年的寿命中一个人能接受上限为15GB的符号数据。 没有人能在有生之年阅读完这些数据,更别提从中发现些什么了。 真正有科学价值的不是用图、表展示的数据,而是由数据作为印证的、抽象的科学思想。 实验在其中只起到了验证的作用,可以说不仅不是一等公民,甚至很多时候只是第二性的——科学研究中常常是先提出抽象的科学思想,才有特别设计的实验去验证真伪。
其二,将论文误解为一种工作量证明(PoW):实验是我攻读研究生期间写了代码干了活的直接证明材料,统统列上来作为我向老板、领导的工作汇报。 这样就是将自己在科学研究中的身份搞错了。 研究生不是力工。 科学探索不是出卖苦力,科学工作的一分耕耘大多数时候都不会有对应的一分收获产生(否则会被大家鄙称为“灌水”),对比工作量意义有限。 论文应该是创造性思想的载体,而不是对付雇主的打卡记录——前者将是富有科学价值的文献,后者除了付你工资的雇主之外再没有人会关心。 你的导师、评阅专家、答辩会成员、学位会成员,以及你论文未来潜在的读者,他们是不是你的雇主?他们关心的是什么,想看到的是什么? 写论文之前,一定要首先搞清这一点。
当然同学也会问:你说这些有什么用,谁不知道要写出科学价值,可我的工作就是平凡到凑不齐三个研究点,怎么办? 这里就得提醒还没临近毕业大限的同学,要有意识地避免落到这样的境地里来。 写学位论文一定要预先谋划,前期开展研究工作的时候就在同一领域内布局好三个研究点的大致内容,在导师的指导下开展一项工作,然后有针对性地开展另外一到两项的研究。 只要你完成了一项有价值的研究工作,就很容易延伸出三个研究点了,例如:以该工作本身作为第二点;查找该工作的缺陷,继续完善,是第三点;总结两项工作的思想,提出科学、凝练的形而上(模型、范式、原则、风格),是第一点。 其中形而上的部分完全可以在论文写作的过程中一同完成。
最差的情况下,也要保持实事求是。有几项工作就写几项,实验就原原本本地用来验证具体的工作内容,不要把实验提出来凑章节。
与之前九项不同,最后一项是一条建议性的内容,因此提出了唯一一项正相关的指标。 将文章写得富有条理、线索明确并非一件容易的事。 但是我们有一种快速改进的方法:强迫自己将文章每一处的线索明确地列出来,写在各级标题的下方。 我们拿相关工作来举例:
2 相关工作
这一章介绍某领域的重要相关工作,以便读者理解后文内容。从某方面来看,某领域的研究工作大致可以分为甲、乙、丙;从某某方面来看,这些工作又可以按照某因素分为子、丑、寅、卯。本章将按某一顺序逐一简要介绍。笔者建议对某领域有兴趣的读者,可以阅读[18]作更深入的了解。
2.1 甲
解决某领域问题的一种较为直观的方式,是采用甲。甲具有A、B、C的特点,因此曾广泛应用于X [19]、Y [20]、Z [21]等。
谁[22]提出了甲子,怎么样。但是具有什么问题。
为了解决这一问题,谁[23]又提出了甲丑……
……
2.2 乙
虽然甲怎样怎样,但是如何如何。因此,自某年后,研究者开始转向乙。与甲不同的是,乙具有D、E、F的特点……
……
采用这种写法,读者每读到一处,都可以从标题下方的文字获得局部内容的阅读指引,阅读体验将会显著改善。 而更重要的是,有意识地遵循这种固定写法,可以强迫你对文章的叙述脉络进行整理。 只要能写得出来,就能保证文章是有结构、有条理、有逻辑的。 这种写法带来的特点是各级标题下都有一段导引性文字,不会有任何两个标题直接相邻。因此,我用标题间最小距离来刻画这一特点。
学位论文是同学们一生中独一无二的材料,论文代表了自己获取学位时的学术水平,在数据库中随时供人查阅参考。 虽然大家对我的博士论文给了比较高的评价,但我的论文里还是犯了以上一些错误; 学会将我的论文出版成册,再次校对的过程让我感到非常懊悔。 建议同学们还是应当将学位论文写作当作自己的一件人生大事去对待,用多少热情去仔细琢磨都不为过。
这一次我只是简单地从批判的角度来讨论论文写作,相对而言,建设性并不强。 希望同学们读到这些内容,经过思考后,能够体会到论文的基本要求,建立对论文基本的审美判断。 看到自己的不足之处是进步的基础;认识到论文写作需要遵循诸多限制、需要多下功夫,才能建立正确的心态。
上个月,我受教育处李丹老师邀请,面向毕业生做了一次学位论文写作和答辩心得报告,里面包含更多建设性的意见。 因为当时时间比较匆忙,其中很多内容还不完整或欠缺打磨。 学位论文写作是一项需要长远规划的重要工作,写好论文最重要的是要整理好自己的多项研究工作,而这些研究工作又需要从开展研究之初就进行谨慎的选题和谋划。 因此我认为类似的报告不应当放在五月、面向毕业生开展,而更应当放在九月、面向入学新生开展。 我计划争取在九月前将内容补充完整,然后再进行分享。
在科学计算任务中,既需要处理高精度(数百至数百万比特)数值数据,也需要处理低精度数据(科学智能算法中引入的深度神经网络)。我们判断支撑未来科学计算新范式,需要一种不同于深度学习处理器的新体系结构。

我们对高精度数值计算的应用特性进行分析,发现存在“反内存墙”现象:数据传输瓶颈总是出现在近端存储层次上。这是因为数值乘法的数据局部性极强,如果运算器件原生支持的字长不够长,就需要分解运算,产生巨额的中间结果访存请求。因此,新架构必须具有:1. 处理数值乘法的能力;2. 一次性处理更大字长的能力;3. 能够高效处理大量低精度数据。 针对这些需求,我们设计了Cambricon-P架构。

Cambricon-P架构具有以下特点:
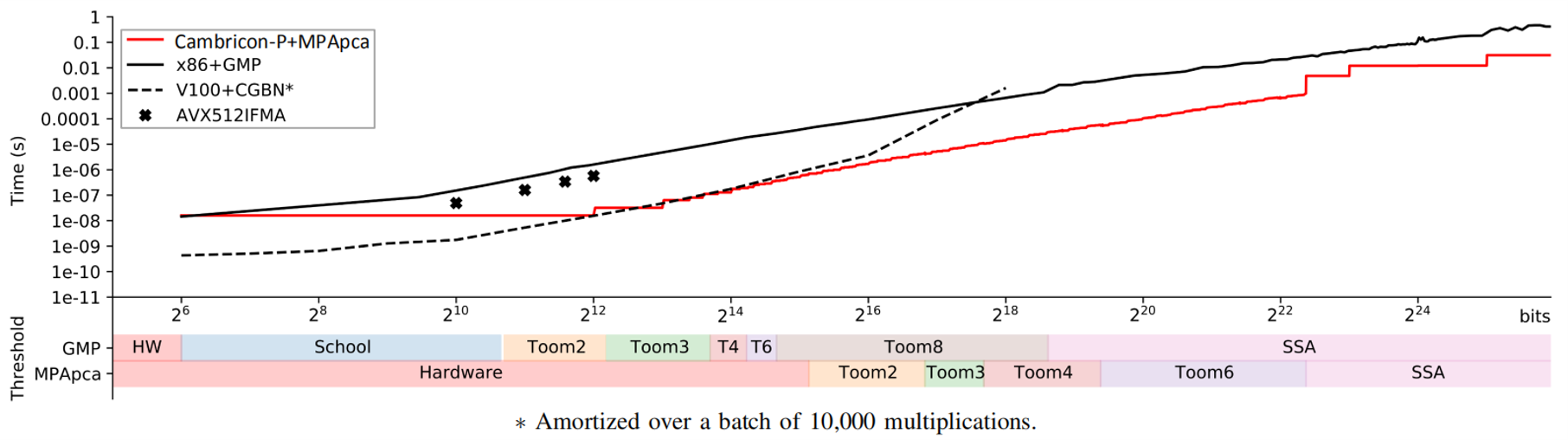
为实现更大规模架构支持更大字长,Cambricon-P整体架构采用分形方式设计,在核级、处理单元(PE)级、内积运算单元(IPU)级复用相同控制结构和相似的数据流。我们为Cambricon-P原型快速开发了配套运算库MPApca,实现了图姆-库克2/3/4/6快速乘法算法和颂哈吉-施特拉森快速乘法算法(SSA),以便与CPU+GMP、GPU+CGBN等现有高性能计算系统进行对比评估。
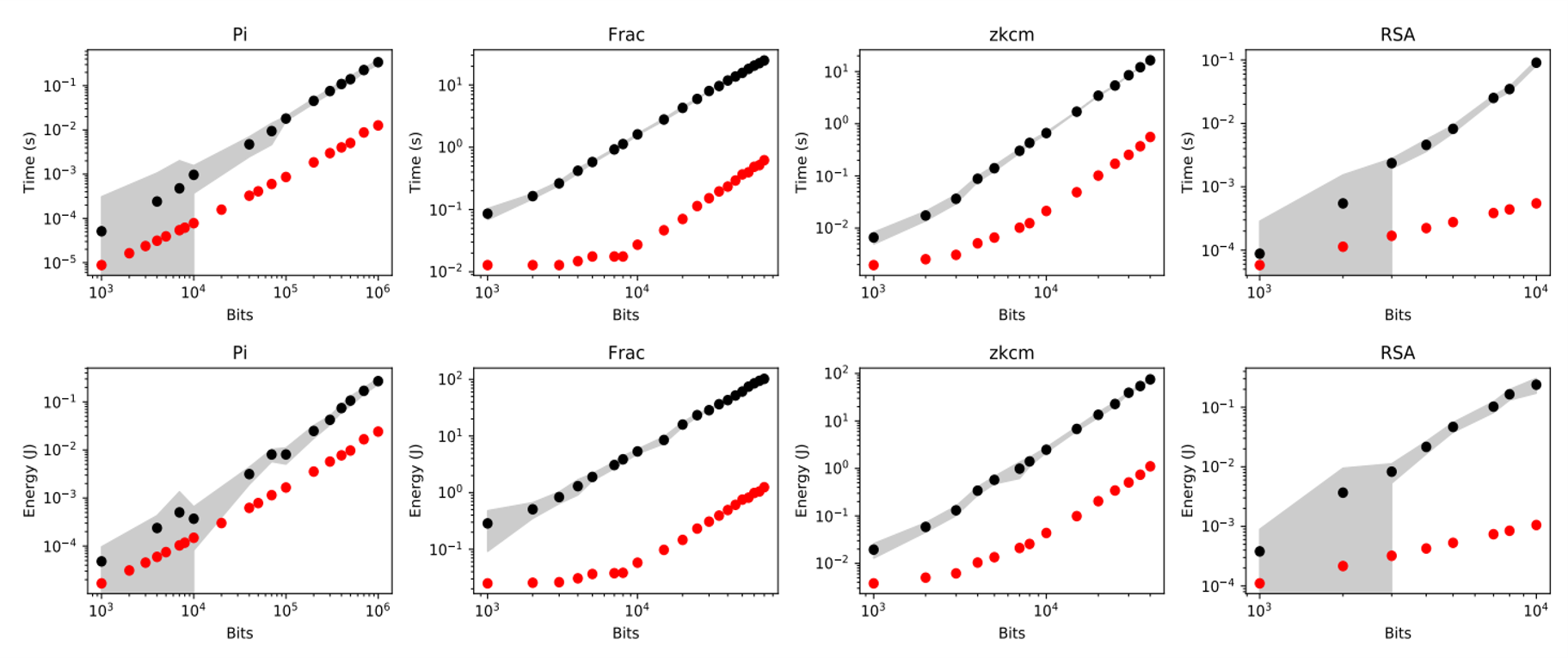
实验结果表明,Cambricon-P+MPApca在单个乘法运算时相比CPU+GMP最大加速达100.98倍,在四个典型应用上平均实现加速23.41倍、能效提升30.16倍。
论文发表在MICRO 2022。[DOI]
自1968年创办以来,55届MICRO会议总共收录论文1900余篇。Cambricon-P获评大会最佳论文Runner-up奖,这是中国大陆研究团队第四次提名MICRO最佳论文。
在上海交通大学李超老师的邀请下,我参加了第一届CCF Chips大会的“体系结构优秀青年学者论坛”,并作线上报告。 我分享了一篇在审(单盲)论文《Rescue to the Curse of Universality》的成果和延伸思考。 内容还未完成同行评议过程,仅供参考。
报告要点:
根据半导体周期规律,我们预测接下来深度学习处理器将向通用性、易用性、标准化、系统化方向发展。
在西宁,我碰见了季宇,他也是CCF优博。 他一见到我就提了很多问题:那么复杂的系统,怎么可能就用分形来刻画呢?你在寒武纪真的是这么做的? 时间有限,我和他解释说,分形是并行计算里非常基础的本质特征,而不是我们刻意制造的概念。 在当日的新人脱口秀环节中,我也重新为分形做了一个新定义:分形(并行计算)是问题的一种基本性质,指能够用一段有限的程序控制任意规模的并行计算机、在有限时间内计算任意大的问题。
不止是季博士,很多同行也都有类似的疑惑。不能服人,是因为我的工作仍然还在非常初级的阶段。我必须承认,现在对一线开发者而言,分形计算系统的概念实践意义有限。 但是,我有一言(确信):如果你的系统不是分形的,那你要小心了!
分形的基本要求是用同一套程序跑在任意大的机器上。不分形,对一个并行机各部分分别编程,会引来很奇怪的情况: 额外的程序会根本性地让计算过程变质。因为在计算理论中,它们可以作为建议串。理论计算机学家立刻就明白这是什么含义了,我将对工程师们再多解释一点。
以MPMD模型为例。
既然有
这个算法在有限时间内判定停机问题。
如果你的系统不允许发生这种事情(判定非递归问题;你当然不应该允许发生这种事情),那么它就已经是分形的了,即使形式上可能和我在论文中描述的不一致。 根本问题在于,超额的程序是有害的——理论上它会导致能够计算不可计算问题,实践中导致的问题有多种形式:包括我们曾经在寒武纪遇到的每年一重构即是根源于此(Cambricon-F:一种具有分形冯·诺伊曼体系结构的机器学习计算机)。 分形计算系统是在反对这种错误实践。
希望这段论述能让分形的概念更清楚一些。
去年在做 Cambricon-Q:量化训练架构 的工作时,我发现许多同学不会做误差估计,也没有意识到随机实验中需要进行误差估计。体系结构领域似乎并不重视这一点,同行做实验时常常在真实系统上测试跑一个几十毫秒的程序,然后直接用time命令截取用时,再汇报模拟实验结果的加速比。这样的测量是有误差的,结果常常在一个范围内波动;如果加速比达到上百倍,一点误差可能会导致最终报告出完全不同的数值。
小初高通识教育中,实验课会教我们“多次测量取平均值”,但“多次”应该是多少次?5次够吗?10次呢?100次呢?还是直到工作截稿之前,一直重复做下去呢?我们需要了解科学的实验方法:重复随机实验中的误差估计。我发现并非所有本科概率论课程都教授这些,但要从事科学研究工作,这却是一项必备技能。
我不是统计学家,本科时我也是全校挂科王,肯定算不上概率论专家。但我曾经作为业余爱好钻研过蒙特卡洛模拟,我来展示我自己是如何完成这个过程的。如果有误,还请概率论专家们不吝纠正。
我们有一组实验测量值
虽然分布参数中有
虽然以上推演过程首先假设了高斯分布,但是根据列维-林德伯格中心极限定理(Levy-Lindeberg CLT),任意无限个随机变量叠加后,其和都趋近于服从高斯分布,只要这些随机变量满足以下两个条件:
这样,无论实验测量值实际服从的分布是什么,我们都可以直接从CLT导出最终
高斯分布告诉我们,我们有99.7%的把握说,
我们用到的常数3和99.7%是查表得出的高斯分布累积分布函数(CDF)上的一个点,类似常用值还有1.96和95%。从确定的置信区间推算置信度,我们使用CDF:
编程实现时,高斯分布的CDF可以比较直接地用数学库函数erf实现。它的逆函数erfinv并不常见,在C语言和C++的标准库里就不存在,不过因为CDF都是连续、单调、可导的,其导函数即概率密度函数(PDF),因此用牛顿法、割线法、二分法等数值方法都可以比较高效地求逆。
然而,以上估计完全依赖于CLT,CLT毕竟只描述了一个极限情况。实际实验时我们取5次、10次实验结果,离无限次实验差得远,难道也强行应用CLT吗?这显然不科学。
描述有限多次随机实验叠加值,有一个更专用的概率分布,即“学生” t-分布。除了以上高斯估计推算的过程,t-分布还额外考虑了
t-分布与自由度直接相关,在重复随机实验里自由度可以理解为
当试验次数不多时,我们直接用t-分布代替高斯分布来描述
在Python中,直接调包:高斯估计使用scipy.stats.norm.cdf和scipy.stats.norm.ppf;“学生” t-分布估计使用scipy.stats.t.cdf和scipy.stats.t.ppf。
C++里比较难做,STL库功能不全,而且引入外部库不方便。下面的代码给出了两种误差估计的C++实现。两条注释条之间的内容可以抽出组成一个头文件供直接使用,更下面的部分则展示了一个样例程序:从
1 | /* |
由于现代深度学习技术的不断发展,深度学习任务具有控制逻辑复杂化、宿主-设备交互频繁化的发展趋势;而传统的以CPU为中心的加速器系统宿主-设备交互开销大,交互速度提升缓慢,最终形成“交互墙”问题:交互速度提升与设备计算速度提升之间形成剪刀差。根据阿姆达尔定律,这将严重限制加速器的应用。
针对这一问题,CPULESS加速器提出了融合流水线结构,将系统的控制中心移至深度学习处理器上来,省去独立的宿主CPU芯片;采用面向异常编程方式,能够将标量控制单元和向量运算单元之间的交互开销降至最低。
实验表明,在多种具有复杂控制逻辑的现代深度学习任务上,CPULESS系统相比传统以CPU为中心的GPU系统能够实现10.30倍性能提升,并节约92.99%的能耗。
为本站设计的点击计数器,就是页面底部的那个。 虽然我估计如今99%的人和MNIST打交道时都是使用Python的, 但本站承诺不使用Python,选择用C++实现了这个小功能。 整个做下来体验并不比Python复杂太多,料想能节约不少碳排放😁。
下载MNIST测试集,用gzip解压。
因为LeCun说测试集的前5000个比较容易识别,所以程序里只使用了这5000个。
访问次数记录在名为fcounter.db的文件里,
每一位数字从测试集中随机抽选,组成PNG图片
(这里使用了Magick++来比较方便地生成PNG),
然后通过FastCGI接口返回给webserver。
1 |
|
以上代码就贡献给Public Domain了。
libmagick++-dev libfcgi-dev;-lfcgi++ -lfcgi;magick++-config提供的编译选项。我用spawn-fcgi来启动编译出来的二进制(在systemd里通过设置服务,自动启动)。
主流的webserver都支持FastCGI接口,设置一个FastCGI反向代理,指向spawn-fcgi启动的端口,部署配置就完成了。
我用的是Caddy:
1 | reverse_proxy /counter.png localhost:21930 { |
把/counter.png加在页面底部HTML里,每次刷新页面都能观察到数字增加;
如果浏览器缓存了图片,在链接之间跳转不触发对服务器的访问,数字就不会增加。