During the work as a software architect in the Cambricon Tech,
I deeply realized the pain points of software engineering.
When I first took over in 2016, the core software was developed by me and WANG Yuqing, with 15,000 lines of code;
when I left in 2018, the development team increased to more than 60 people, with 720,000 lines of code.
From the perspective of lines, the complexity of software doubles every 5 months.
No matter how much manpower is added, the team is still under tremendous development pressure:
customer needs are urgent and need to be dealt with immediately;
New features need to be developed, the accumulated old code needs to be refactored;
the documentation has not yet been established; the tests have not yet been established…
I may not be a professional software architect, but who can guarantee that the future changes are foreseen from the very beginning?
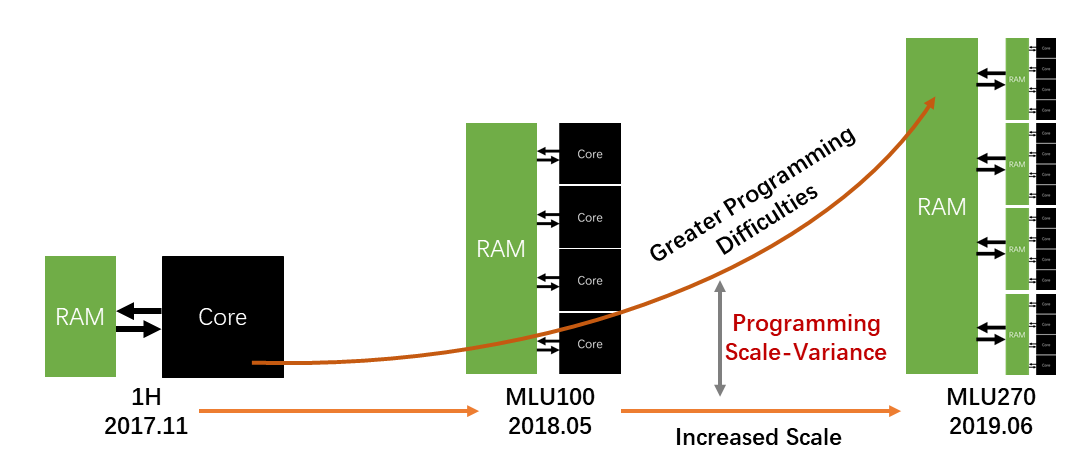
Just imagine: the underlying hardware was single-core; it became multi-core a year later; then it became NUMA another year later.
With such a rapid evolution, how can the same software be able to keep up without undergoing thorough refactoring?
The key to the problem is that, the scale of the hardware has increased, so the level of abstraction that needs to be programmed and controlled is also increasing, making programming more complicated.
We define the problem as the programming scale-variance.
In order to solve this problem from engineering practices, we started the research, namely Cambricon-F.
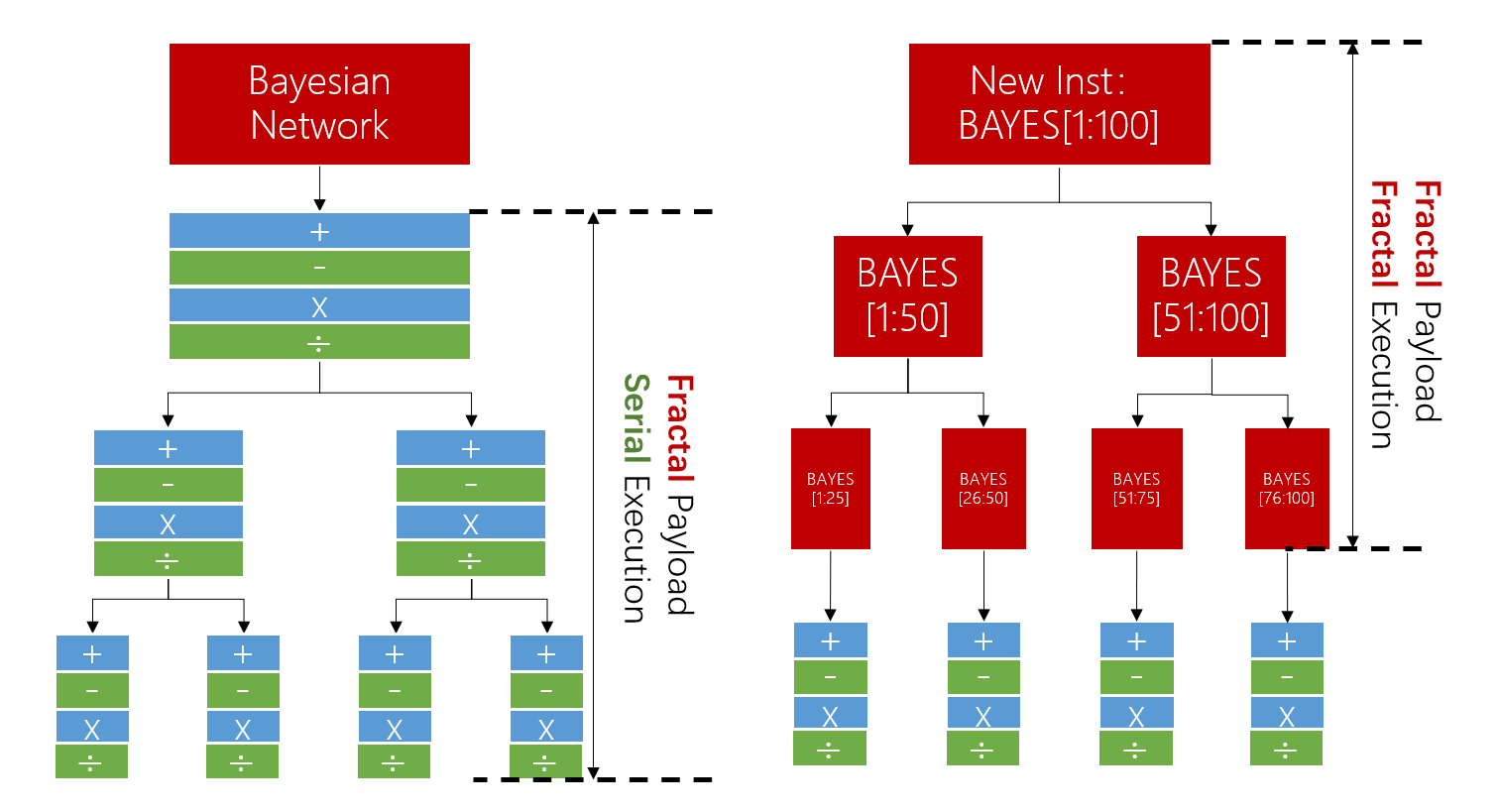
Addressing the scale-variance of programming, it is necessary to introduce some kinds of scale invariants.
The invariant we found is fractal: the geometric fractals are self-similar on different scales.
We define the workload in a fractal manner, so does the hardware architecture. Both scale invariants can be zoomed freely until a scale that is compatible with each other is found.
Cambricon-F first proposed the Fractal von Neumann Architecture. The key features of this architecture are:
- Sequential code, parallel execution adapted to the hardware scale automatically;
- Programming Scale-invariance: hardware scale is not coded, therefore code transfers freely between different Cambricon-F instances;
- High efficiency retained by fractal pipelining.
Published on ISCA 2019. [DOI]